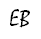I’ve discussed how David Gay’s strtod() function computes an initial floating-point approximation and then uses a loop to check and correct it, but I have not discussed how the correction is made. That is the last piece of the strtod() puzzle, and I will cover it in this article.
When the Approximation Needs Adjusting
strtod() checks if the floating-point approximation it computes is correct, that is, within one-half binary ULP from the decimal input. Symbolically that means if d is the decimal input, b is its floating-point approximation, and h is one-half ULP, then
|d – b| ≤ h
strtod() uses arbitrary-precision integer arithmetic to make that check, so it scales those three numbers by a common factor that makes them all integers (if they’re not all integers already). This gives the equivalent inequality
|dS – bS| ≤ hS
When that inequality fails to hold, the approximation needs adjusting.
(strtod() actually computes |bS – dS|, which is equivalent; but I prefer presenting it as I have.)
How Much Do You Adjust the Approximation By?
strtod()’s mission is to adjust b so that it becomes the correctly rounded result r, that is, the closest double-precision floating-point number to d. It does this by computing the distance between d and b and then adding that to b (the distance is negative when d < b).
To compute the distance, strtod() first computes the number of ULPs between d and b. (In this context a ULP is the relative distance between two floating-point numbers; for example, adjacent floating-point numbers differ by one ULP.) The distance is the number of ULPs times the size of the gap between floating-point numbers around b.
The information strtod() needs to calculate the number of ULPs lies in the big integer variables dS, bS, and hS: d is (dS – bS)/hS half-ULPs away from b, which divided by two gives the number of ULPs.
Approximating the Adjustment to the Approximation
Big integer division is expensive, so strtod() does a floating-point calculation that approximates (dS – bS)/hS. (By using floating-point, the risk is that the adjustment will be slightly off — but that’s what the correction loop is for.)
strtod() creates two floating-point integers: one that approximates dS – bS, and another that approximates hS. Since strtod() stores big integers in pure binary form, this is easily done: the significant bits are set to the first 53 bits of the big integer (no rounding is done), and the power of two exponent is set to the big integer’s length in bits, minus one.
Actually, what strtod() does for the exponents is this: based on the length of the two big integers, it computes their common power of two factor, which it then removes before setting their floating-point exponents. These smaller — yet proportional — floating-point integers are then divided using IEEE floating-point division.
strtod() performs this calculation in its b2d() and ratio() functions. It manipulates the big integer and floating-point values in their raw binary forms.
Example: 1.0372157551632929e-112
For the decimal input 1.0372157551632929e-112, strtod() produces an initial estimate that is 9 ULPs below the correct answer, which it then corrects on its first attempt — that is, with only one iteration of the correction loop. Here’s how it plays out:

The initial approximation b is
1.11111110110110101101001000110111011011001011101111 x 2-373
which as a hexadecimal floating-point constant is 0x1.fedad2376cbbcp-373.
The correctly rounded result r is
1.1111111011011010110100100011011101101100101111000101 x 2-373
which is 0x1.fedad2376cbc5p-373.
(You can see that these two numbers are 9 ULPs apart by looking at their hexadecimal representations, for example. They differ only in their last two digits, which are 0xc5 and 0xbc; 0xc5 – 0xbc = 9.)
The Big Integers
These are the big integers used for the inequality:
dS = 5282114521221424076214776576041131483370935327274031523113715020111615202935726632918375605604984423448576 bS = 5282114521221418711390904183884753269307412749890806844246175615065208575060751172713935375213623046875000 dS - bS = 5364823872392156378214063522577383224678867539405046406627874975460204440230391361376573576 hS = 293873587705571876992184134305561419454666389193021880377187926569604314863681793212890625
The Floating-Point Approximations to the Big Integers
Here are the pure binary representations of the two big integers we need to approximate:
dS - bS (binary) = 10101000100011011001011111101111101010101001010010011011111110101001001111111001101000000001100011101010110000001111100011111010000001000010100011000101000110011101100001110111010101011100100001010010000110001010100101101100110011011101011100110011101101010000101011111101110101100010110101100010001000 hS (binary) = 1001001110111010010001111100100110000000111010011000110011011111110001100110111100110011011011000011011010110001000000010011011100000010001101001111001111111101011110110000100011011101001110010000101111000011110001010100111000111111010000001111011111100110010000100100101110100101010011111000000001
The 53 bits of double-precision are the 53 most significant bits of each big integer (highlighted). The power of two exponents are 301 and 297, respectively, since the binary representation of dS – bS is 302 bits, and the binary representation of hS is 298 bits. Here are what the two approximations would be:
dS - bS (double-precision) = 1.0101000100011011001011111101111101010101001010010011 x 2301 = 1.3168210907216788552176467419485561549663543701171875 x 2301 hS (double-precision) = 1.0010011101110100100011111001001100000001110100110001 x 2297 = 1.1541223272232168373108152081840671598911285400390625 x 2297
However, strtod() removes the common power of two factor 2297, making these the actual floating-point integers it creates:
dS - bS (double-precision) = 1.3168210907216788552176467419485561549663543701171875 x 24 = 21.069137451546861683482347871176898479461669921875 hS (double-precision) = 1.1541223272232168373108152081840671598911285400390625
The Floating-Point Division
Those two double-precision numbers are now divided in IEEE floating-point:
dS - bS (double-precision) ----------------------------------------- = hS (double-precision)
21.069137451546861683482347871176898479461669921875 ------------------------------------------------------ 1.1541223272232168373108152081840671598911285400390625 = approx 18.255549654115578
That is the difference in half-ULPs, so we divide it by two to get approximately 9.1277748270577888 ULPs.
The Adjustment
The amount strtod() adds to b to get r is the number of ULPs times the size of the gap between floating-point numbers around b. In this example, the gap size is 2-425, which is the place value of the 53rd bit position of b (which is 1/252 of the place value of the first bit position, 2-373). Therefore, the adjustment is approximately 9.13 x 2-425. Due to rounding, adding this is the same as adding 9 x 2-425 — 9 ULPs.
The fractional part of the adjustment is used as a stopping test. If it is “close” to 0.5, the loop must continue, since we can’t say for sure which side of 0.5 we’re on. In this example, the loop ends because the fractional part is not close to 0.5.
Discussion
Here are a few additional points:
- When the distance between d and b is less than one ULP, the adjustment is set to (plus or minus) one ULP. This works because, to get to this adjustment phase, big integer arithmetic has already determined conclusively that d and b are more than one-half ULP apart. In other words, b must be altered by one ULP.
- d and b could cross a power of two boundary, but there’s no need to check for this. The adjustment calculation is independent of gap size (gap size cancels out).
- The adjustment calculation is not done in cases where “bigcomp” applies (bigcomp applies only when the truncated value of d is within one-half ULP above b).
- strtod() has to handle overflow and underflow when adjusting approximations near DBL_MAX or 2-1074 (the smallest double), respectively.
- The maximum adjustment is 10 ULPs or so.
Java Does It Differently
Java’s decimal to floating-point conversion routine, the doubleValue() method of its FloatingDecimal class, takes a simpler — but less efficient — approach. Instead of doing the above calculation, it simply adjusts its approximation by one ULP and continues to loop.