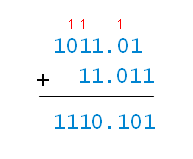
This is the first of a four part series on “pencil and paper” binary arithmetic, which I’m writing as a supplement to my binary calculator. This article introduces binary arithmetic, and then discusses binary addition.
Binary Numbers, Binary Code, and Binary Logic
This is the first of a four part series on “pencil and paper” binary arithmetic, which I’m writing as a supplement to my binary calculator. This article introduces binary arithmetic, and then discusses binary addition.
SQLite has a limited-precision floating-point to decimal conversion routine which it uses to print double-precision floating-point values retrieved from a database. As I’ve discovered, its limited-precision conversion results in decimal numbers of 15 significant digits or less that won’t round-trip. For example, if you store the number 9.944932e+31, it will print back as 9.94493200000001e+31.
SQLite also has a limited-precision decimal to floating-point conversion routine, which it uses to convert input decimal numbers to double-precision floating-point numbers for storage in a database. I’ve found that some of its conversions are incorrect — by as many as four ULPs — and that some decimal numbers fail to round-trip because of this; “garbage in, garbage out” as they say.
Continue reading “Incorrect Decimal to Floating-Point Conversion In SQLite”
I’ve discovered that decimal floating-point numbers of 15 significant digits or less don’t always round-trip through SQLite. Consider this example, executed on version 3.7.3 of the pre-compiled SQLite command shell:
sqlite> create table t1(d real);
sqlite> insert into t1 values(9.944932e+31);
sqlite> select * from t1;
9.94493200000001e+31
SQLite represents a decimal floating-point number that has real affinity as a double-precision binary floating-point number — a double. A decimal number of 15 significant digits or less is supposed to be recoverable from its double-precision representation. In SQLite, however, this guarantee is not met; this is because its floating-point to decimal conversion routine is implemented in limited-precision floating-point arithmetic.
Continue reading “Fifteen Digits Don’t Round-Trip Through SQLite Reals”
What does this C function do?
double f(double a)
{
double b, c;
b = 10*a - 10;
c = a - 0.1*b;
return (c);
}
Based solely on reading the code, you’ll conclude that it always returns 1: c = a – 0.1*(10*a – 10) = a – (a-1) = 1. But if you execute the code, you’ll find that it may or may not return 1, depending on the input. If you know anything about binary floating-point arithmetic, that won’t surprise you; what might surprise you is how far from 1 the answer can be — as far away as a large negative number!
Continue reading “The Answer is One (Unless You Use Floating-Point)”
In my article “Quick and Dirty Decimal to Floating-Point Conversion” I presented a small C program that uses double-precision floating-point arithmetic to convert decimal strings to binary floating-point numbers. The program converts some numbers incorrectly, despite using an algorithm that’s mathematically correct; its limited precision calculations are to blame. I dubbed the program “quick and dirty” because it’s simple, and overall converts reasonably accurately.
For this article, I took a similar approach to the conversion in the opposite direction — from binary floating-point to decimal string. I wrote a small C program that combines two mathematically correct algorithms: the classic “repeated division by ten” algorithm to convert integer values, and the classic “repeated multiplication by ten” algorithm to convert fractional values. The program uses double-precision floating-point arithmetic, so like its quick and dirty decimal to floating-point counterpart, its conversions are not always correct — though reasonably accurate. I’ll present the program and analyze some example conversions, both correct and incorrect.
Continue reading “Quick and Dirty Floating-Point to Decimal Conversion”
Double rounding is when a number is rounded twice, first from n0 digits to n1 digits, and then from n1 digits to n2 digits. Double rounding is often harmless, giving the same result as rounding once, directly from n0 digits to n2 digits. However, sometimes a doubly rounded result will be incorrect, in which case we say that a double rounding error has occurred.
For example, consider the 6-digit decimal number 7.23496. Rounded directly to 3 digits — using round-to-nearest, round half to even rounding — it’s 7.23; rounded first to 5 digits (7.2350) and then to 3 digits it’s 7.24. The value 7.24 is incorrect, reflecting a double rounding error.
In a computer, double rounding occurs in binary floating-point arithmetic; the typical example is a calculated result that’s rounded to fit into an x87 FPU extended precision register and then rounded again to fit into a double-precision variable. But I’ve discovered another context in which double rounding occurs: conversion from a decimal floating-point literal to a single-precision floating-point variable. The double rounding is from full-precision binary to double-precision, and then from double-precision to single-precision.
In this article, I’ll show example conversions in C that are tainted by double rounding errors, and how attaching the ‘f’ suffix to floating-point literals prevents them — in gcc C at least, but not in Visual C++!
Continue reading “Double Rounding Errors in Floating-Point Conversions”
For correctly rounded decimal to floating-point conversions, many open source projects rely on David Gay’s strtod() function. In the default rounding mode, IEEE 754 round-to-nearest, this function is known to give correct results (notwithstanding recent bugs, which have been fixed). However, in the less frequently used IEEE 754 directed rounding modes — round toward positive infinity, round toward negative infinity, and round toward zero — strtod() gives incorrectly rounded results for some inputs.
Continue reading “Incorrect Directed Conversions in David Gay’s strtod()”
When a decimal number is converted to a binary floating-point number, the floating-point number, in general, is only an approximation to the decimal number. Large integers, and most decimal fractions, require more significant bits than can be represented in the floating-point format. This means the decimal number must be rounded, to one of the two floating-point numbers that surround it.
Common practice considers a decimal number correctly rounded when the nearest of the two floating-point numbers is chosen (and when both are equally near, when the one with significant bit number 53 equal to 0 is chosen). This makes sense intuitively, and also reflects the default IEEE 754 rounding mode — round-to-nearest. However, there are three other IEEE 754 rounding modes, which allow for directed rounding: round toward positive infinity, round toward negative infinity, and round toward zero. For a conversion to be considered truly correctly rounded, it must honor all four rounding modes — whichever is currently in effect.
I evaluated the Visual C++ and glibc strtod() functions under the three directed rounding modes, like I did for round-to-nearest mode in my articles “Incorrectly Rounded Conversions in Visual C++” and “Incorrectly Rounded Conversions in GCC and GLIBC”. What I discovered was this: they only convert correctly about half the time — pure chance! — because they ignore the rounding mode altogether.
Continue reading “Visual C++ and GLIBC strtod() Ignore Rounding Mode”
Visual C++ rounds some decimal to double-precision floating-point conversions incorrectly, but it’s not alone; the gcc C compiler and the glibc strtod() function do the same. In this article, I’ll show examples of incorrect conversions in gcc and glibc, and I’ll present a C program that demonstrates the errors.
Continue reading “Incorrectly Rounded Conversions in GCC and GLIBC”
In my analysis of decimal to floating-point conversion I noted an example that was converted incorrectly by the Microsoft Visual C++ compiler. I’ve found more examples — including a class of examples — that it converts incorrectly. I will analyze those examples in this article.
Continue reading “Incorrectly Rounded Conversions in Visual C++”
In my article “Quick and Dirty Decimal to Floating-Point Conversion” I presented a small C program that converts a decimal string to a double-precision binary floating-point number. The number it produces, however, is not necessarily the closest — or so-called correctly rounded — double-precision binary floating-point number. This is not a failing of the algorithm; mathematically speaking, the algorithm is correct. The flaw comes in its implementation in limited precision binary floating-point arithmetic.
The quick and dirty program is implemented in native C, so it’s limited to double-precision floating-point arithmetic (although on some systems, extended precision may be used). Higher precision arithmetic — in fact, arbitrary precision arithmetic — is needed to ensure that all decimal inputs are converted correctly. I will demonstrate the need for high precision by analyzing three examples, all taken from Vern Paxson’s paper “A Program for Testing IEEE Decimal–Binary Conversion”.
Continue reading “Decimal to Floating-Point Needs Arbitrary Precision”
This little C program converts a decimal value — represented as a string — into a double-precision floating-point number:
#include <string.h>
int main (void)
{
double intPart = 0, fracPart = 0, conversion;
unsigned int i;
char decimal[] = "3.14159";
i = 0; /* Left to right */
while (decimal[i] != '.') {
intPart = intPart*10 + (decimal[i] - '0');
i++;
}
i = strlen(decimal)-1; /* Right to left */
while (decimal[i] != '.') {
fracPart = (fracPart + (decimal[i] - '0'))/10;
i--;
}
conversion = intPart + fracPart;
}
The conversion is done using the elegant Horner’s method, summing each digit according to its decimal place value. So why do I call it “quick and dirty?” Because the binary floating-point value it produces is not necessarily the closest approximation to the input decimal value — the so-called correctly rounded result. (Remember that most real numbers cannot be represented exactly in floating-point.) Most of the time it will produce the correctly rounded result, but sometimes it won’t — the result will be off in its least significant bit(s). There’s just not enough precision in floating-point to guarantee the result is correct every time.
I will demonstrate this program with different input values, some of which convert correctly, and some of which don’t. In the end, you’ll appreciate one reason why library functions like strtod() exist — to perform efficient, correctly rounded conversion.
Continue reading “Quick and Dirty Decimal to Floating-Point Conversion”