Which is bigger, 64! or 264? 64! is, because it follows from a proof by induction for any integer n greater than or equal to 4. It’s also easy to just reason that 64! is bigger: 264 is 64 factors of 2, whereas 64! has 64 factors, except all but one of them (1) are 2 or greater.
When I saw this problem though I wondered if I could solve it in another way: Could the factors of two alone in 64! be greater than 264? As it turns out, almost.
I have been writing about the spacing of decimal and binary floating-point numbers, and about how their relative spacing determines whether numbers round-trip between those two bases. I’ve stated an inequality that captures the required spacing, and from it I have derived formulas that specify the number of digits required for round-trip conversions. I have not proven that this inequality holds, but I will prove “half” of it here. (I’m looking for help to prove the other half.)
In a computer, decimal floating-point numbers are converted to binary floating-point numbers for calculation, and binary floating-point numbers are converted to decimal floating-point numbers for display or storage. In general, these conversions are inexact; they are rounded, and rounding is governed by the spacing of numbers in each set.
Floating-point numbers are unevenly spaced, and the spacing varies with the base of the number system. Binary floating-point numbers have power of two sized gaps that change size at power of two boundaries. Decimal floating-point numbers are similarly spaced, but with power of ten sized gaps changing size at power of ten boundaries. In this article, I will discuss the spacing of decimal floating-point numbers.
An IEEE 754 binary floating-point number is a number that can be represented in normalized binary scientific notation. This is a number like 1.00000110001001001101111 x 2-10, which has two parts: a significand, which contains the significant digits of the number, and a power of two, which places the “floating” radix point. For this example, the power of two turns the shorthand 1.00000110001001001101111 x 2-10 into this ‘longhand’ binary representation: 0.000000000100000110001001001101111.
The significands of IEEE binary floating-point numbers have a limited number of bits, called the precision; single-precision has 24 bits, and double-precision has 53 bits. The range of power of two exponents is also limited: the exponents in single-precision range from -126 to 127; the exponents in double-precision range from -1022 to 1023. (The example above is a single-precision number.)
Limited precision makes binary floating-point numbers discontinuous; there are gaps between them. Precision determines the number of gaps, and precision and exponent together determine the size of the gaps. Gap size is the same between consecutive powers of two, but is different for every consecutive pair.
Gaps Between Binary Floating-Point Numbers In a Toy Floating-Point System
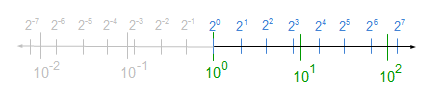
I showed how the positive powers of ten and two are interleaved, and said that the interleaving of the negative powers of ten and two is its mirror image. In this article, I will show you why, and prove that the same properties hold.
Powers of Ten and Two in Logarithmic Scale (Nonpositive Powers Highlighted)
To truly understand decimal to binary and binary to decimal conversion, you should know how the powers of ten and the powers of two relate. In particular, you should know how they are interleaved. The interleaving explains why, for example, the number of bits required to represent an n-digit decimal integer varies. Consequently, it also explains why 9,007,199,254,740,991 (253 – 1) is representable in binary floating-point, and why 9,007,199,254,740,993 (253 + 1) is not.
Powers of Ten and Two in Logarithmic Scale (Nonnegative Powers Highlighted)
In my article “Composing Powers of Two Using The Laws of Exponents” I showed how to combine powers of two using the standard laws of exponents. There are two other rules I use when combining powers of two; I call them the add duplicate power of two rule and the subtract half power of two rule. These are nonstandard rules, applying only to powers of two. Although these are special cases of the existing multiplication and division rules, I’ve found value in recognizing them in addition and subtraction form. I’ll state these rules and show examples of their usage.
In my article “Using Integers to Check a Floating-Point Approximation,” I briefly mentioned “bigcomp,” an optimization strtod() uses to reduce big integer overhead when checking long decimal inputs. bigcomp does a floating-point to decimal conversion — right in the middle of a decimal to floating-point conversion mind you — to generate the decimal expansion of the number halfway between two target floating-point numbers. This decimal expansion is compared to the input decimal string, and the result of the comparison dictates which of the two target numbers is the correctly rounded result.
In this article, I’ll explain how bigcomp works, and when it applies. Also, I’ll talk briefly about its performance; my informal testing shows that, under the default setting, bigcomp actually worsens performance for some inputs.
For decimal inputs that don’t qualify for fast path conversion, David Gay’s strtod() function does three things: first, it uses IEEE double-precision floating-point arithmetic to calculate an approximation to the correct result; next, it uses arbitrary-precision integer arithmetic (AKA big integers) to check if the approximation is correct; finally, it adjusts the approximation, if necessary. In this article, I’ll explain the second step — how the check of the approximation is done.
David Gay’s strtod() function does decimal to floating-point conversion using both IEEE double-precision floating-point arithmetic and arbitrary-precision integer arithmetic. For some inputs, a simple IEEE floating-point calculation suffices to produce the correct result; for other inputs, a combination of IEEE arithmetic and arbitrary-precision arithmetic is required. In the latter case, IEEE arithmetic is used to calculate an approximation to the correct result, which is then refined using arbitrary-precision arithmetic. In this article, I’ll describe the approximation calculation, which is based on a form of binary exponentiation.
Hexadecimal floating-point constants, also known as hexadecimal floating-point literals, are an alternative way to represent floating-point numbers in a computer program. A hexadecimal floating-point constant is shorthand for binary scientific notation, which is an abstract — yet direct — representation of a binary floating-point number. As such, hexadecimal floating-point constants have exact representations in binary floating-point, unlike decimal floating-point constants, which in general do not †.
Hexadecimal floating-point constants are useful for two reasons: they bypass decimal to floating-point conversions, which are sometimes doneincorrectly, and they bypass floating-point to decimal conversions which, even if done correctly, are often limited toa fixed number of decimal digits. In short, their advantage is that they allow for direct control of floating-point variables, letting you read and write their exact contents.
In this article, I’ll show you what hexadecimal floating-point constants look like, and how to use them in C.